Securing the Future:
The Challenge of Safeguarding LLM Systems

Large Language Models (LLMs) are redefining how we interact with technology, powering applications from customer support to healthcare solutions. But with great power comes great responsibility—and significant security risks. It’s easy to see the immense potential of LLMs, but it’s equally crucial to reflect on their vulnerabilities, and how we can ensure their safe deployment.
When we discuss LLMs, it’s important to first distinguish between an LLM and an LLM system. At first glance, the difference might seem subtle, but it’s critical when assessing risks and determining how to protect these technologies. An LLM is, essentially, a sophisticated algorithm—designed to sift through large datasets, detect patterns, and generate predictions based on those patterns. It’s the core technology, and while powerful, its structure is relatively simple.
An LLM system, on the other hand, is a more complex entity. It’s not just the model, but a larger framework that incorporates the model along with other components, like data pipelines, interfaces, and application logic. The system is where the vulnerabilities start to multiply, and this is where we need to focus our attention.
The Simple Yet Powerful LLM: A Vulnerability in Disguise
When you look at the LLM itself, its design might seem straightforward. Typically, when you download a model, you’re downloading two things: the definition of the model itself and its “weights.” These weights are essentially arrays of numbers that define the model’s configuration.
Once these components are loaded by inference software, the model is ready to process inputs and return predictions. These inputs can be text, images, or even sounds, all of which are processed by the model to generate output.
On the surface, this architecture seems fairly minimal, with a limited attack surface. The primary interaction point is the LLM’s input layer. If the model is secure, and if the weights and definitions are loaded correctly and safely, the risk of a direct exploit seems low.
However, early versions of LLMs faced significant issues. For example, weights for some open models were initially distributed as Python pickle objects, which could execute commands when loaded. This vulnerability led to incidents like the “Sleepy Pickle” exploit, where attackers subtly poisoned machine learning models.
Today, these risks have been mitigated with safer storage formats, like safetensors, which prevent code execution during the loading process.
Still, the inherent simplicity of the LLM does not mean we can ignore the potential for manipulation. Even with these improved safeguards, the real threats often arise once the model is integrated into a larger system.
The Challenge of Prompt Injections: Unavoidable Risks
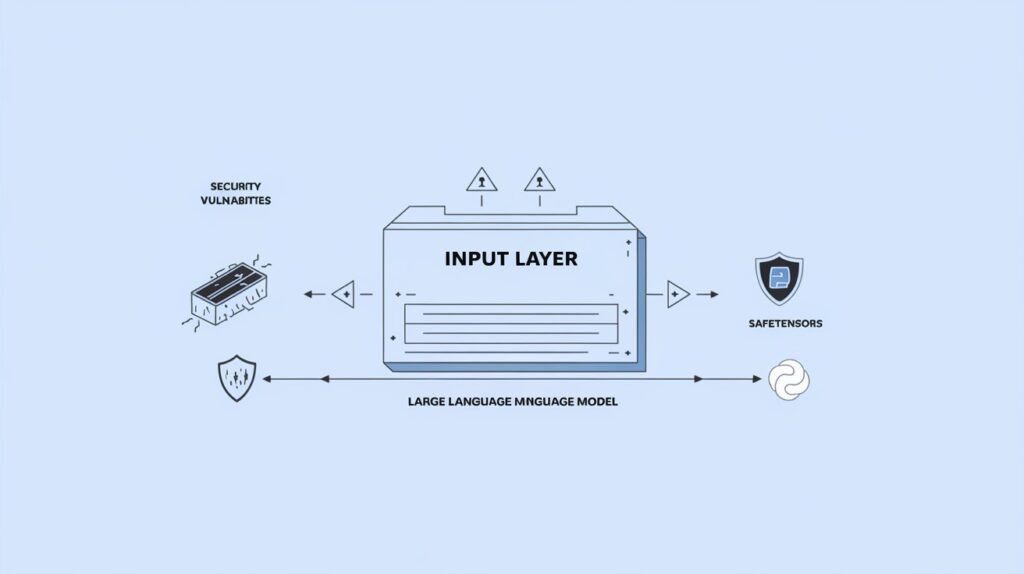
One of the most significant risks associated with LLM systems comes from prompt injections. Unlike traditional security flaws that can be patched, prompt injections are a fundamental challenge.
Essentially, prompt injections occur when an external entity crafts a prompt that manipulates the model’s behavior in unintended ways. These vulnerabilities cannot be fully fixed or eliminated because the very nature of an LLM system allows for such manipulations.
This creates an interesting paradox: Even if an LLM is designed with the most rigorous safety standards, there’s always the possibility that a prompt could bypass these safeguards.
In these cases, the model might return unsafe or harmful output, which could have significant consequences, particularly if that output is used without proper validation. This is why it’s crucial to always treat the outputs from LLMs as potentially untrustworthy until they have been validated.
When a prompt injection happens, the result isn’t just a failure in the LLM model itself; it can trigger a broader security vulnerability within the entire LLM system. The lesson here is that no matter how secure an individual model is, it is only as secure as the system that houses it.
LLM Systems: Complexity Breeds Risk
The real security issues often arise when LLMs are incorporated into larger systems. These systems combine the AI-driven LLM with other non-AI components, creating more pathways for exploitation. In a typical LLM system, the output from an LLM might be used directly by the system or passed along to other components. Here, the security risks multiply.
The output from an LLM is rarely the end of the story. It often serves as input for subsequent processes. This means that any flaw in the LLM’s output could cascade through the system. Take, for example, a scenario where an LLM generates code for a specific task, like creating a diagram. If that code has security flaws or bugs, they could be executed when the code is compiled, leading to potential data breaches or system failures.
This is where post-processing mechanisms become essential. By running generated code in a sandbox or analyzing it with security tools before executing it in production, we can mitigate these risks.
In complex systems, even the most secure models need a layer of oversight. It’s no longer enough to just trust that the LLM will behave as expected; the system needs to be designed with the understanding that LLM outputs should always be treated with caution.
Guarding the Gates: Ensuring Safe LLM Outputs
One of the more promising developments in LLM security is the rise of “guardrails” for runtime protection. These tools act as an additional layer of security, monitoring both the inputs and outputs of the LLM. When a user inputs a prompt, the guardrails analyze it for any signs of malicious intent or prompt injections. Similarly, when the LLM generates output, the guardrails review it for safety concerns, blocking, modifying, or logging unsafe responses.
The effectiveness of these guardrails depends on their ability to detect and respond to risks in real time. Open-source solutions like Guardrails AI, NeMo-Guardrails, and even IBM’s granite-guardian models are playing an essential role in this area, offering specialized tools for identifying and mitigating threats both during training and at runtime. As LLM systems continue to evolve, it’s clear that incorporating these kinds of safety mechanisms will become an industry standard.
Towards a Secure Future
As LLM systems continue to proliferate across industries, securing them will require a combination of vigilance, innovation, and collaboration. It’s vital to recognize that securing an LLM is not just about protecting the model itself, but the entire system that surrounds it. Outputs must always be treated with caution, as they could be manipulated or inherently flawed. Validating and safeguarding these outputs should be a top priority.
At the same time, we need to embrace open-source tools and frameworks that help us measure and mitigate risks in real time. By incorporating solutions like TrustyAI, lm-evaluation-harness, and granite-guardian, we can ensure that LLM systems are not only functional but safe.
In the coming years, we’ll continue to see innovations in AI security that will help shape the future. Where these technologies can be deployed with confidence. The task before us is not just to advance AI, but to do so responsibly, ensuring that every step forward is also a step toward a safer, more secure digital ecosystem.